

En tant qu'entreprise de big data qui puise dans des dizaines de sources de données pour construire l'outil d'analyse de données de l'industrie musicale, Soundcharts est confronté quotidiennement à des métadonnées corrompues. Au fil des années, nous avons développé plusieurs algorithmes pour garantir que notre base de données soit aussi propre que possible, mais nous devons encore assurer une maintenance manuelle permanente. L'équipe Soundcharts a appris à ses dépens à quel point les métadonnées musicales peuvent être défaillantes — en gérant une base de données de plus de 2 millions d'artistes.
Mais ce n'est pas qu'une question qui nous concerne. Le fait est que les problèmes de métadonnées causent d'énormes dommages à l'industrie. Des métadonnées corrompues nuisent à l'expérience utilisateur sur les services de streaming, amputent une partie des revenus d'édition, privent les auteurs-compositeurs d'une reconnaissance méritée — et ce n'est que le début. Mais commençons par les bases :
Qu'est-ce qu'une métadonnée musicale ?
Les métadonnées musicales sont les données d'identification intégrées dans un fichier musical, composées de centaines de balises textuelles attachées via des conteneurs de métadonnées (ID3v1 et ID3v2 étant de loin les plus répandus), détaillant tout, du nom de l'artiste et de la date de sortie du titre aux genres associés et aux crédits des auteurs-compositeurs.
À première vue, les métadonnées peuvent sembler insignifiantes, mais considérez ceci. Chaque fois qu'un utilisateur recherche une chanson sur Spotify ; chaque fois que BMI attribue des redevances d'exécution ; chaque fois que l'algorithme de Pandora met une chanson en file d'attente — les métadonnées entrent en jeu. C'est l'huile qui fait tourner les rouages de l'industrie.
3 types de métadonnées musicales
En général, les métadonnées musicales peuvent être divisées en trois types principaux :
1. Métadonnées descriptives
Les métadonnées descriptives décrivent le contenu de l'enregistrement, avec des balises textuelles objectives telles que le titre de la chanson, la date de sortie, le numéro de piste, l'artiste interprète, la pochette, le genre principal, etc. Elles ont environ un million d'applications différentes. Les métadonnées descriptives sont utilisées chaque fois que quelqu'un doit interroger, organiser, trier ou présenter de la musique — que ce soit pour constituer une page artiste sur Spotify, construire une médiathèque organisée, ou identifier et attribuer un passage radio.
Les problèmes de métadonnées descriptives sont les plus visibles pour l'utilisateur final. Si vous avez utilisé un service de streaming assez longtemps, vous avez probablement déjà rencontré des erreurs résultant de descriptions corrompues. Pensez aux chansons de plusieurs artistes différents mélangées sur la même page artiste Spotify, aux pages artistes composites, aux noms de chansons mal orthographiés, aux dates de sortie erronées — toutes ces erreurs sont les conséquences de métadonnées descriptives corrompues. De tels problèmes sèment la confusion chez le consommateur — mais ce n'est que la partie visible de l'iceberg.
2. Métadonnées de propriété et de droits d'exécution
Qu'il s'agisse de streams numériques, de passages radio ou de synchronisation cinématographique, de nombreuses parties — des artistes interprètes aux paroliers, producteurs et auteurs-compositeurs — se partagent les revenus. D'où la nécessité des métadonnées de propriété, qui précisent les accords contractuels derrière la sortie aux fins du calcul (et de la répartition) des redevances. Les métadonnées de propriété sont là pour s'assurer que chaque partie impliquée dans le processus de création musicale est rémunérée en conséquence.
Compte tenu de la nature complexe des partages derrière la plupart des titres (ainsi que des différences de législation à travers le monde), diviser correctement le dollar du consommateur est déjà un défi en soi. Maintenant, si l'on ajoute des métadonnées manquantes ou incohérentes, le problème devient dix fois plus compliqué. Les problèmes de métadonnées de propriété touchent là où ça fait le plus mal : une erreur humaine ici, un dysfonctionnement de base de données là — et un auteur-compositeur peut manquer des dizaines de milliers de dollars.
Mais ce n'est qu'une partie du problème. Les crédits d'artistes sont aussi le principal moyen pour les auteurs-compositeurs, producteurs, musiciens de session et ingénieurs de se rendre visibles dans l'industrie musicale, une sorte d'espace de promotion « B2B ». Des métadonnées de propriété corrompues privent les musiciens à la fois d'argent et de reconnaissance.
3. Métadonnées de recommandation
Les deux premiers types de balises de métadonnées sont objectifs — il n'existe qu'un seul nom de chanson réel, et qu'une seule liste de crédits. Les métadonnées de recommandation sont différentes. Elles consistent essentiellement en des balises subjectives visant à refléter le contenu de l'enregistrement et à décrire comment il sonne. Étiquettes d'humeur, balises de genre génératives, scores de similarité entre chansons — les métadonnées de recommandation servent à établir des connexions pertinentes entre les titres et à alimenter les moteurs de recommandation.
Bien sûr, d'autres types de métadonnées peuvent également améliorer la découverte musicale. Les dates de sortie peuvent aider à détecter la musique de la même époque, et un nom de producteur commun peut aider à trouver des enregistrements similaires. Cependant, la distinction essentielle réside dans l'origine des métadonnées de recommandation.
La découverte est un différenciateur majeur entre les services de streaming. C'est pourquoi les balises de métadonnées de recommandation sont généralement des données propriétaires qui ne circulent pas dans l'industrie comme le font les métadonnées descriptives et de propriété. Au contraire, chaque plateforme aura sa propre approche de génération de métadonnées de recommandation et sa propre base de données derrière l'algorithme de recommandation. Ainsi, si les métadonnées descriptives et de propriété sont créées côté artiste, les métadonnées de recommandation sont produites par les DSP (ou leurs affiliés).
Par exemple, Pandora adopte une approche de classification humaine avec son Music Genome Project. Spotify, en revanche, utilise un mélange de données générées par les utilisateurs et de balises de découverte The Echo Nest, produites grâce à une combinaison d'apprentissage automatique et de curation humaine. Pour avoir un aperçu de la structure des balises de métadonnées de recommandation de The Echo Nest/Spotify, consultez le projet Organize Your Music.
Les métadonnées de découverte constituent le sous-ensemble qui se développe le plus rapidement dans l'ensemble du paysage. Les nouvelles technologies repoussent les frontières de la découverte, appelant à de nouvelles solutions et approches en matière de recommandation.
Pensez simplement à la façon dont les enceintes connectées vont changer la façon dont nous accédons à la musique et la découvrons. La consommation musicale médiée par la voix fait passer les utilisateurs des requêtes textuelles structurées aux demandes amorphes du type « Alexa, joue quelque chose que j'aime ». Cela représente un nouveau défi pour les moteurs de recommandation des plateformes de streaming et des moteurs de recherche comme Google. Il ne suffira plus de trouver des chansons similaires et de générer des files d'attente de chansons façon radio. Les plateformes de streaming devront déterminer quelle est la meilleure chanson à jouer pour cette personne précise à ce moment précis. La façon dont elles relèveront ce défi affectera le quotidien de milliers d'artistes et de professionnels de la musique, façonnant l'avenir de l'industrie musicale pour les années à venir.

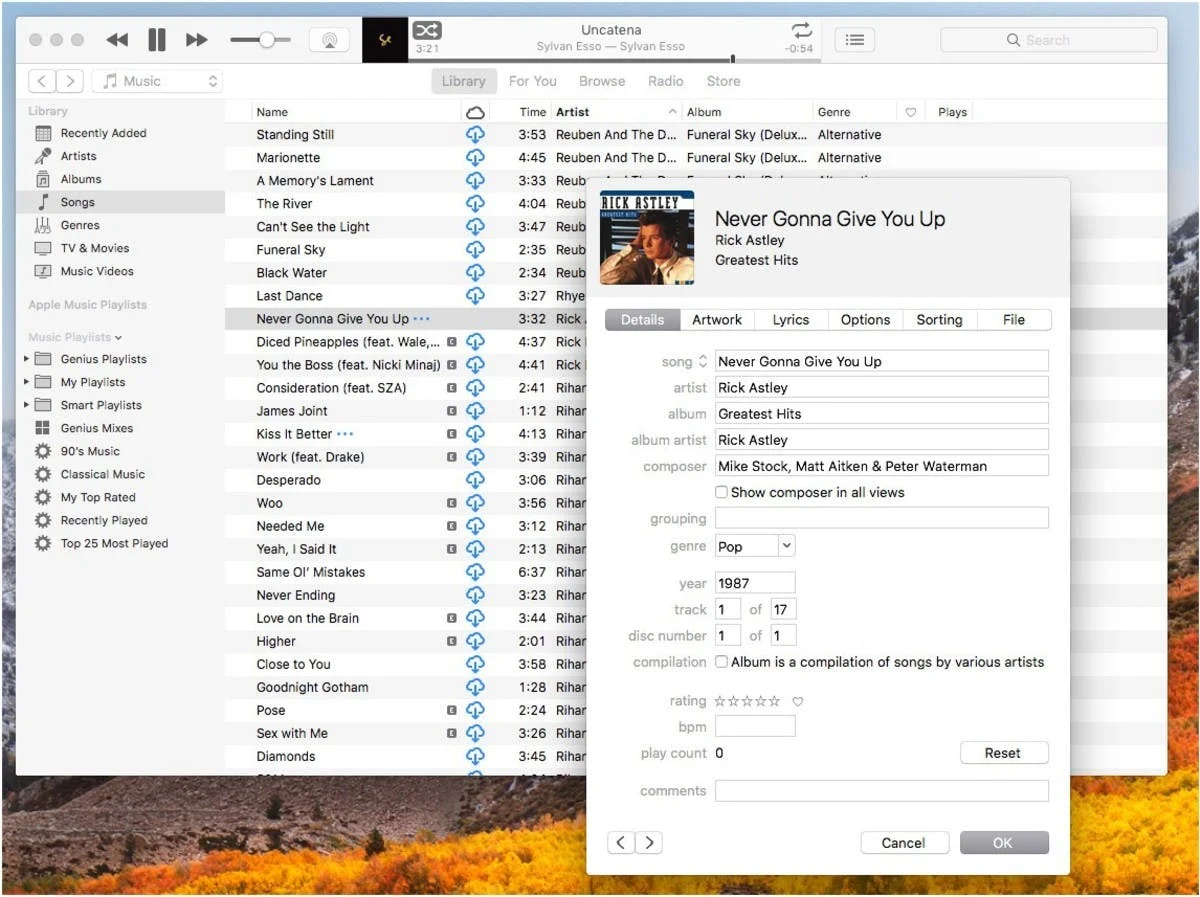
Erreurs d'artistes composites en action
Les problèmes des métadonnées musicales
À ce stade, un lecteur curieux pourrait se demander : si les métadonnées musicales sont si essentielles pour le business musical, pourquoi ne les a-t-on pas encore corrigées ? Pourquoi les auteurs-compositeurs perdent-ils encore de l'argent et pourquoi la base de données iTunes est-elle pleine d'erreurs d'artistes composites ? Eh bien, le fait est que le système de gestion des métadonnées musicales a toujours été à la traîne des formats de distribution audio.
Par exemple, quand le CD est apparu, il ne permettait aucune balise au-delà des données descriptives de base — les boîtiers et livrets de CD jouaient le rôle de support de métadonnées. Puis Napster a pris le dessus, et le chaos a suivi. Les fichiers MP3 (ou FLAC) extraits des CD n'avaient pratiquement aucune métadonnée attachée, et encore moins en passaient les réseaux P2P, créant une immense archive de fichiers audio mal balisés.
1. Absence de standardisation des bases de données
Puis, la musique numérique est entrée en scène et a remplacé les formats d'enregistrement physiques. Tous les acteurs de l'industrie ont commencé à stocker et à échanger des données, mais à l'époque, personne ne voyait vraiment la nécessité de normes de métadonnées unifiées. Tous les différents magasins numériques, labels, éditeurs, PRO et distributeurs ont créé leurs propres bases de données — et les services de streaming ont suivi leurs traces.
À ce jour, il n'existe pas de structure de base de données unifiée. Les métadonnées circulent à travers un enchevêtrement non standardisé de bases de données dans l'industrie : des labels aux distributeurs, des distributeurs aux DSP, des DSP aux PRO, des PRO aux éditeurs.
Toutes ces parties échangent des données, mais les colonnes et champs de leurs bases de données ne correspondent pas toujours. Imaginez qu'une base de données reçoive une valeur dans le champ « Choriste » — alors que sa propre colonne correspondante s'appelle « Chœurs ». Les algorithmes ne pourront pas faire la correspondance (sauf s'il existe une règle spécifique pour cela) et dans 99 % des cas, le crédit du choriste sera simplement supprimé. Une grande partie des métadonnées se perd en chemin dans la chaîne de données musicales.
De plus, pour chaque entreprise musicale, il est rare qu'il n'y ait qu'une seule base de données. Les données sont plutôt stockées dans plusieurs bibliothèques musicales internes sous différents formats — et doivent donc être ajustées et validées pour mettre en place un échange adéquat avec les bases de données externes.
Le système de gestion des métadonnées actuel a été créé dans le sillage de la musique numérique, à une époque où personne ne savait vraiment comment le paysage allait évoluer. Puis la production de données a crû de manière exponentielle. Aujourd'hui, 20 000 chansons sont publiées chaque jour et transitent par ce système complexe de bases de données plus ou moins compatibles — générant des milliers d'erreurs.
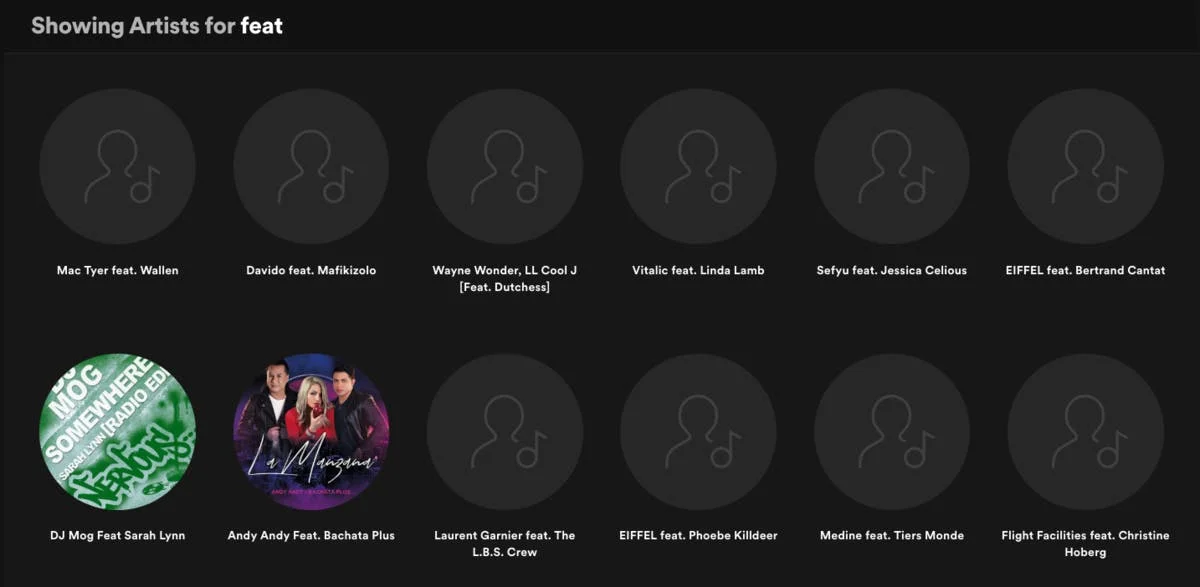
Rassurez-vous, Spotify ne fait pas mieux
2. La multiplicité des données musicales
Le problème n'est même pas qu'il y ait 20 000 chansons. C'est aussi le fait que ces chansons peuvent être différentes variations d'une même œuvre musicale. Devenons un peu techniques pour un moment. Chaque chanson est structurée à travers trois niveaux d'abstraction :
- Une œuvre musicale ou composition — le fruit du processus de création intellectuelle des auteurs-compositeurs et des producteurs, le pain et le beurre des éditeurs musicaux.
- Un enregistrement sonore de l'œuvre musicale, produit et enregistré par des artistes interprètes. L'enregistrement sonore est une expression particulière de l'œuvre musicale.
- Une sortie — une manifestation spécifique et emballée de l'enregistrement sonore.
Tout commence donc par les auteurs-compositeurs et les compositeurs qui créent une œuvre musicale. Cette composition peut ensuite s'exprimer de cent façons différentes — pensez aux reprises, aux remixes, aux éditions radio, etc. De plus, chacun de ces enregistrements sonores peut sortir en single, faire partie d'un album, d'une édition deluxe, d'une compilation, etc.
Au final, une seule composition peut générer des centaines (voire des milliers) d'entités de métadonnées distinctes, ce qui complique considérablement le paysage. Les entreprises musicales doivent faire correspondre tous ces différents niveaux d'abstraction. Par exemple, si ASCAP reçoit un rapport de passage radio pour une sortie spécifique, il doit l'associer à la composition sous-jacente pour localiser les auteurs-compositeurs.
3. Les limites du standard d'identification musicale
On pourrait penser que l'industrie musicale aurait développé un standard pour pouvoir identifier quelle sortie est une version de quel enregistrement sonore et faire correspondre tous les niveaux d'abstraction. Pas vraiment.
Actuellement, le principal standard d'identification musicale dans tous les formats de fichiers est le code ISRC — « un point de référence fixe lorsque l'enregistrement est utilisé dans différents services, à travers les frontières ou dans le cadre de différents accords de licence ». Cependant, les codes ISRC sont attribués aux enregistrements sonores — seulement l'un des niveaux des données musicales.
Sur la seule base de l'ISRC, vous ne pouvez pas savoir quelle est l'œuvre musicale originale derrière cet enregistrement particulier. Il ne permet pas d'agréger les entrées au niveau d'abstraction supérieur pour compiler toutes les versions du même titre ou de la même composition. Les limites du standard ISRC rendent extrêmement difficile pour les entreprises musicales la correction des métadonnées défaillantes. Pour donner du sens aux données entrantes, les acteurs du secteur doivent s'appuyer sur des balises de métadonnées descriptives pour associer l'ISRC à d'autres identifiants persistants, comme l'UPC pour les sorties ou l'ISWC pour les compositions. Cela génère toutes sortes d'erreurs, de doublons et de conflits dans la chaîne de données musicales.
Il y a eu plusieurs tentatives de créer une base de données de référence musicale mondiale, mais à ce jour, il n'existe pas de source de vérité ultime permettant de résoudre les conflits de métadonnées. Actuellement, les bases de données musicales publiques les plus notables sont les plateformes open-source MusicBrainz et Discogs ainsi que le catalogue de codes ISRC de l'IFPI — mais, malheureusement, toutes sont loin d'être complètes.
Les lacunes du système d'identification signifient que les entreprises musicales doivent faire des acrobaties chaque fois qu'elles rencontrent une erreur de métadonnées. Tenter de relier les points par recoupement de bases de données elles-mêmes truffées d'incohérences est la routine quotidienne de la gestion des données musicales. Si tant est que l'entreprise s'en préoccupe.

La section Crédits de Spotify met en évidence les problèmes de métadonnées de propriété
4. Les erreurs humaines
Dernier point, mais non des moindres : ce que certains appelleraient le maillon le plus faible de tout système. La plupart des métadonnées descriptives et de propriété sont créées et saisies manuellement. Compte tenu de l'échelle, cela entraîne inévitablement toutes sortes de fautes de frappe, de noms mal orthographiés, de titres erronés, de dates de sortie incorrectes — ou même de données tout simplement manquantes.
Prenez les données de propriété, par exemple. Les crédits d'une chanson peuvent devenir extrêmement complexes, avec des dizaines d'auteurs-compositeurs, d'ingénieurs, de musiciens de session et de producteurs différents travaillant sur la même sortie. En même temps, les délais n'attendent pas — et les accords de propriété et les partages sont souvent négligés quand l'équipe cherche à publier le nouveau titre à temps. Très souvent, les partages sont décidés après coup — et une fois la chanson sortie, il est extrêmement difficile d'ajouter ou de modifier les métadonnées.
Tous ces facteurs — des erreurs humaines et de l'incompatibilité des bases de données aux standards d'identification défaillants et à la nature multipartite des droits musicaux — créent la sombre réalité des métadonnées musicales modernes. L'épine dorsale de l'industrie musicale est peut-être le plus grand désordre que le monde des données ait jamais connu.
Comment corriger les métadonnées ?
La situation actuelle perdant-perdant appelle à un changement. Des métadonnées propres pourraient aider un musicien de session à décrocher le prochain engagement, payer le loyer de l'auteur-compositeur, optimiser l'expérience utilisateur des services de streaming — et économiser des millions à l'industrie au passage. Cependant, il n'y a pas de réponse claire sur la façon dont nous allons régler le problème. Ne soyez pas trop pessimiste pour autant — plusieurs entreprises, initiatives et organisations travaillent vers un meilleur système.
Solutions de nettoyage, de gestion et d'administration des métadonnées
Le premier type d'entreprises de métadonnées travaille à la constitution de bases de données musicales, puis au nettoyage, à la correction et à l'enrichissement des balises. Des sociétés comme Gracenote, Musicstory et, dans une certaine mesure, The Echo Nest sont les fournisseurs de métadonnées pour divers DSP dans l'industrie. Ces sociétés s'occupent principalement de métadonnées descriptives et de recommandation. Elles utilisent un mélange d'algorithmes de nettoyage de métadonnées et de technologie de reconnaissance audio pour améliorer la recherche, la constitution de playlists et la découverte musicale, tout en garantissant un affichage correct sur les vitrines numériques.
De l'autre côté de la chaîne de données, des sociétés comme VivaData, Exploration et TuneRegistry élaborent des solutions pour les labels indépendants, les éditeurs et les artistes. Leur objectif est d'aider les entreprises musicales dans la gestion interne des métadonnées, d'auditer les bases de données existantes pour détecter les métadonnées incomplètes ou corrompues, et de rationaliser les flux de données sortants à la racine même du flux de données musicales.
Cependant, toutes ces entreprises traitent les symptômes, et non la cause du problème. Ne vous méprenez pas, il est vital d'essayer de nettoyer le désordre existant — mais cela ne résoudra pas les problèmes systémiques.
De nouveaux standards de bases de données
Le changement le plus significatif viendrait peut-être si nous garantissions que les bases de données de l'industrie musicale sont entièrement compatibles. Cependant, l'optimisation du système de métadonnées à l'échelle de l'industrie nécessiterait une coordination entre toutes les parties du secteur, ce qui est loin d'être simple.
L'acteur le plus visible dans ce domaine est le DDEX, une organisation internationale qui développe et promeut de nouvelles normes et protocoles de données pour optimiser la chaîne de données numérique. Proposant des solutions couvrant l'intégralité du système de données musicales, le DDEX a déjà fait des progrès significatifs, comptant parmi ses membres les plus grands noms de l'industrie. Les standards DDEX visent à faciliter la gestion des métadonnées en studio, à harmoniser les transferts de métadonnées entre les ayants droit et les DSP, et bien plus encore.
En substance, l'objectif de l'organisation est de construire un pipeline complet pour les métadonnées musicales, du point de création jusqu'à la destination finale. La mise en place de protocoles d'échange standard pour les métadonnées musicales pourrait potentiellement débarrasser l'industrie de milliers d'erreurs d'incompatibilité. Cependant, si les initiatives du DDEX peuvent aider à développer un meilleur système, elles ne résoudront pas tous les problèmes de métadonnées.
Pour ne pas paraître cliché, mais quand il s'agit de corriger les métadonnées, il faut commencer par soi-même. Une part considérable des erreurs est due au manque de sensibilisation parmi les professionnels de la musique — ce qui est en partie la raison pour laquelle nous avons rédigé cet article.
Que pouvez-vous faire pour aider à corriger les métadonnées musicales ?
La règle de base est de s'assurer que toutes les métadonnées d'une chanson sont correctement remplies et vérifiées avant la sortie du titre (ou de l'album). Ce n'est pas aussi simple que cela semble. Voici quelques conseils pour vous aider à ne pas contribuer à la pile de métadonnées musicales corrompues :
1. Suivre les métadonnées dès le départ
Chaque chanson peut compter des dizaines (voire des centaines) de contributeurs, et le suivi de toutes les personnes travaillant sur la sortie peut vite devenir ingérable. C'est pourquoi il est crucial de suivre les crédits dès le moment où plus d'une personne est impliquée dans le projet.
Sound Credit et Creator Credits d'Auddly (la fonctionnalité était encore en développement au moment de la rédaction de cet article) peuvent vous aider. Ces solutions permettent d'intégrer les crédits et autres métadonnées directement dans les fichiers DAW qui circulent en studio. Vous pouvez ainsi conserver les crédits au même endroit et maintenir un enregistrement cohérent de toutes les versions de chansons et collaborateurs dans tous les fichiers musicaux.
2. Finaliser les accords et définir les partages avant que la chanson quitte le studio
Les droits musicaux ont tendance à devenir très compliqués, et la précipitation pour respecter la date de sortie peut souvent laisser les métadonnées de propriété incomplètes. Or, des métadonnées de propriété incomplètes peuvent signifier que certains, voire tous les collaborateurs, passeront à côté du paiement. Pour faciliter le volet contractuel, envisagez d'utiliser Splits, une application gratuite créée pour suivre et gérer les collaborateurs d'une chanson et, bien sûr... les partages.
3. S'assurer que les métadonnées sont correctement renseignées
Les fautes de frappe peuvent sembler insignifiantes, mais elles ont un réel impact. La description de la piste sera utilisée pour faire des correspondances dans la base de données, et donc des métadonnées descriptives corrompues ont tendance à tout dérégler. Assurez-vous de vérifier deux fois, voire trois fois, les métadonnées d'une chanson avant de l'envoyer — ou mettez en place un système de validation en deux étapes. Une fois la chanson publiée, corriger les fautes de frappe deviendra très problématique.
4. Suivre les recommandations sur les métadonnées
Il ne s'agit pas seulement de ce que vous saisissez, mais aussi de la façon dont vous formatez ces données. La différence entre écrire le titre d'une chanson comme « Titre de la Chanson (Version Radio) » et « Titre de la Chanson — Version Radio » peut sembler minime, mais considérez ceci. Les données musicales sont comme une pièce pleine de miroirs déformants. Chaque erreur se propagera dans l'industrie musicale, en s'amplifiant au fil du labyrinthe de bases de données. La moindre erreur peut devenir un vrai problème pour un artiste, avec des chansons qui se retrouvent sur la mauvaise page Spotify ou des redevances d'exécution qui se perdent en route.
Pour s'assurer que non seulement le contenu mais aussi les formats sont corrects, vous pouvez utiliser des recommandations sur les métadonnées. Suivez le guide de votre distributeur — la plupart sont faciles à appliquer. Si les instructions du distributeur ne répondent pas à toutes les questions, consultez les recommandations générales comme celles fournies par la Music Business Association.
5. Faire passer le mot
Suivre ces étapes ne résoudra évidemment pas tous les problèmes de métadonnées dans l'industrie. Le problème lui-même est trop complexe, et nous ne pourrons le résoudre que si l'ensemble de l'industrie musicale est sur la même longueur d'onde. En ce sens, la première étape consiste à sensibiliser les professionnels de la musique.
Les métadonnées sont au cœur de l'industrie musicale, et elles sont actuellement défaillantes. Les musiciens ratent des redevances. Les auteurs-compositeurs et les ingénieurs ne reçoivent pas la reconnaissance qu'ils méritent. Les services de streaming ont développé des algorithmes pour s'assurer que le sommet du catalogue paraît propre, mais une fois que l'on plonge en profondeur dans la longue traîne, toutes sortes d'erreurs commencent à apparaître. Nous devons commencer à évoluer vers un meilleur système.
Chez Soundcharts, nous faisons de notre mieux avec le système tel qu'il est. En tant que plateforme d'analyse de données, nous devons collecter des données provenant de dizaines de sources et de bases de données imparfaites. Ensuite, nous agrégerons soigneusement les données et recoupons les balises de métadonnées pour nous assurer que chaque position dans les charts, chaque ajout à une playlist de streaming, chaque passage radio et chaque mention dans la presse numérique est correctement attribué. Nous améliorons continuellement nos algorithmes de nettoyage et de correspondance des métadonnées, tout en maintenant une équipe de maintenance manuelle dédiée pour traiter les problèmes qui passent à travers les mailles du filet. C'est ce qui fait de nous la plateforme d'analyse musicale la plus fiable de l'industrie.

