

Como uma empresa de big data que acessa dezenas de fontes de dados para construir a ferramenta de análise de dados da indústria musical, a Soundcharts lida com metadados corrompidos todos os dias. Ao longo dos anos, desenvolvemos vários algoritmos que garantem que nosso banco de dados seja o mais limpo possível, mas mesmo agora precisamos manter algum tipo de manutenção manual. A equipe da Soundcharts aprendeu da maneira mais difícil o quanto os metadados musicais podem estar quebrados — gerenciando um banco de dados de mais de 2 milhões de artistas.
Mas não se trata apenas de nós. O fato é que os problemas de metadados causam muito dano à indústria. Metadados comprometidos prejudicam a experiência do usuário nos serviços de streaming, cortam uma parcela das receitas de publicação, roubam créditos merecidos dos compositores — e isso é apenas o começo. Mas vamos começar com o básico:
O Que São Metadados Musicais?
Os metadados musicais são os dados de identificação incorporados em um arquivo de música, compostos por centenas de tags de texto que são anexadas por meio de contêineres de metadados (ID3v1 e ID3v2 sendo os mais difundidos), detalhando tudo, desde o nome do artista e a data de lançamento da música até gêneros associados e créditos dos compositores.
A princípio, os metadados podem parecer algo insignificante, mas considere o seguinte. Toda vez que um usuário pesquisa uma música no Spotify; toda vez que a BMI atribui royalties de execução; toda vez que o algoritmo do Pandora enfileira uma música — os metadados estão em ação. É o óleo que faz as engrenagens da indústria girar.
3 Tipos de Metadados Musicais
Em geral, os metadados musicais podem ser divididos em três tipos principais:
1. Metadados Descritivos
Os Metadados Descritivos detalham o conteúdo da gravação, com tags de texto objetivas como título da música, data de lançamento, número da faixa, artista intérprete, capa do álbum, gênero principal e assim por diante. Possui aproximadamente um milhão de aplicações diferentes. Os metadados descritivos são usados toda vez que alguém precisa consultar, organizar, classificar ou apresentar a música — seja para montar uma página de artista no Spotify, construir uma biblioteca musical organizada ou identificar e atribuir uma execução de rádio.
Os problemas de metadados descritivos são os mais visíveis para o usuário final. Se você usa algum serviço de streaming há tempo suficiente, as chances são de que já se deparou com erros resultantes de descrições corrompidas. Pense em músicas de vários artistas misturadas na mesma página de artista do Spotify, páginas de artistas compostas, nomes de músicas com erros ortográficos, datas de lançamento trocadas — tudo isso são consequências de metadados descritivos comprometidos. Esses problemas causam muita confusão para o consumidor — mas isso é apenas a ponta do iceberg.
2. Metadados de Propriedade/Direitos de Execução
Seja se estivermos falando de streams digitais, execuções de rádio ou sincronização de filme, inúmeras partes, desde artistas intérpretes até letristas, produtores e compositores, compartilharão a receita. Daí a necessidade de metadados de propriedade, especificando os acordos contratuais por trás do lançamento para fins de cálculo (e alocação) de royalties. Os metadados de propriedade existem para garantir que cada uma das partes envolvidas no processo de criação musical seja remunerada adequadamente.
Dada a natureza complexa das divisões por trás da maioria das faixas (bem como as diferenças na legislação em todo o mundo), dividir corretamente o dinheiro do consumidor não é tarefa fácil. Agora, se adicionarmos metadados ausentes ou inconsistentes ao mix, o problema fica 10 vezes mais complicado. Os problemas de metadados de propriedade afetam onde mais dói: um erro humano aqui, uma falha no banco de dados ali — e um compositor pode perder dezenas de milhares de dólares.
No entanto, isso é apenas parte do problema. Os créditos do artista também são a principal forma de compositores, produtores, músicos de sessão e engenheiros se tornarem visíveis para a indústria musical, uma espécie de espaço de promoção "B2B". Metadados de propriedade corrompidos roubam dos músicos tanto o dinheiro quanto o crédito.
3. Metadados de Recomendação
Os dois primeiros tipos de tags de metadados são objetivos — há apenas um nome real para a música e apenas uma lista de créditos da música. Os metadados de recomendação são diferentes. Em seu núcleo, consistem em tags subjetivas que visam refletir o conteúdo da gravação e descrever como ela soa. Rótulos de humor, tags de gênero generativas, pontuações de similaridade de músicas — os metadados de recomendação são usados para criar uma conexão significativa entre faixas e alimentar os mecanismos de recomendação.
É claro que outros tipos de metadados também podem ser usados para aprimorar a descoberta de música. As datas de lançamento podem ajudar a detectar músicas da mesma era, e o nome do produtor correspondente pode ajudar a encontrar gravações semelhantes. No entanto, a distinção crítica é a origem dos metadados de recomendação.
A descoberta é um grande diferenciador entre os serviços de streaming. É por isso que as tags de metadados de recomendação geralmente são dados proprietários que não circulam na indústria como os metadados descritivos e de propriedade. Em vez disso, cada plataforma terá sua própria abordagem para gerar metadados de recomendação e seu próprio banco de dados por trás do algoritmo de recomendação. Então, se os metadados de descrição e propriedade são criados no lado do artista, os metadados de recomendação são produzidos pelos DSPs (ou seus afiliados).
Por exemplo, o Pandora adota uma abordagem de classificação humana com seu Music Genome Project. O Spotify, por outro lado, emprega uma mistura de dados gerados pelos usuários e tags de metadados de descoberta do The Echo Nest, produzidas por meio de uma combinação de aprendizado de máquina e curadoria humana. Se quiser ter uma visão das tags de metadados de recomendação da estrutura The Echo Nest/Spotify e ter uma ideia geral de como são os metadados de recomendação, confira o projeto Organize Your Music.
Os metadados de descoberta são o subconjunto de mais rápido desenvolvimento de todo o cenário. A nova tecnologia está expandindo as fronteiras da descoberta, exigindo novas soluções e abordagens para recomendação.
Pense apenas em como os alto-falantes inteligentes mudarão a forma como acessamos e descobrimos música. O consumo de música mediado por voz transforma os usuários de consultas de texto estruturadas para solicitações amorfas como "Alexa, toca algo que eu gosto". Isso traz um novo desafio para os mecanismos de recomendação das plataformas de streaming e mecanismos de busca como o Google. Não será suficiente encontrar músicas semelhantes e gerar filas de músicas semelhantes ao rádio. As plataformas de streaming terão que descobrir qual é a melhor música para tocar para aquela pessoa exata naquele momento exato. A forma como abordam esse desafio afetará os meios de vida de milhares de artistas e profissionais da música, moldando o futuro da indústria musical por anos.

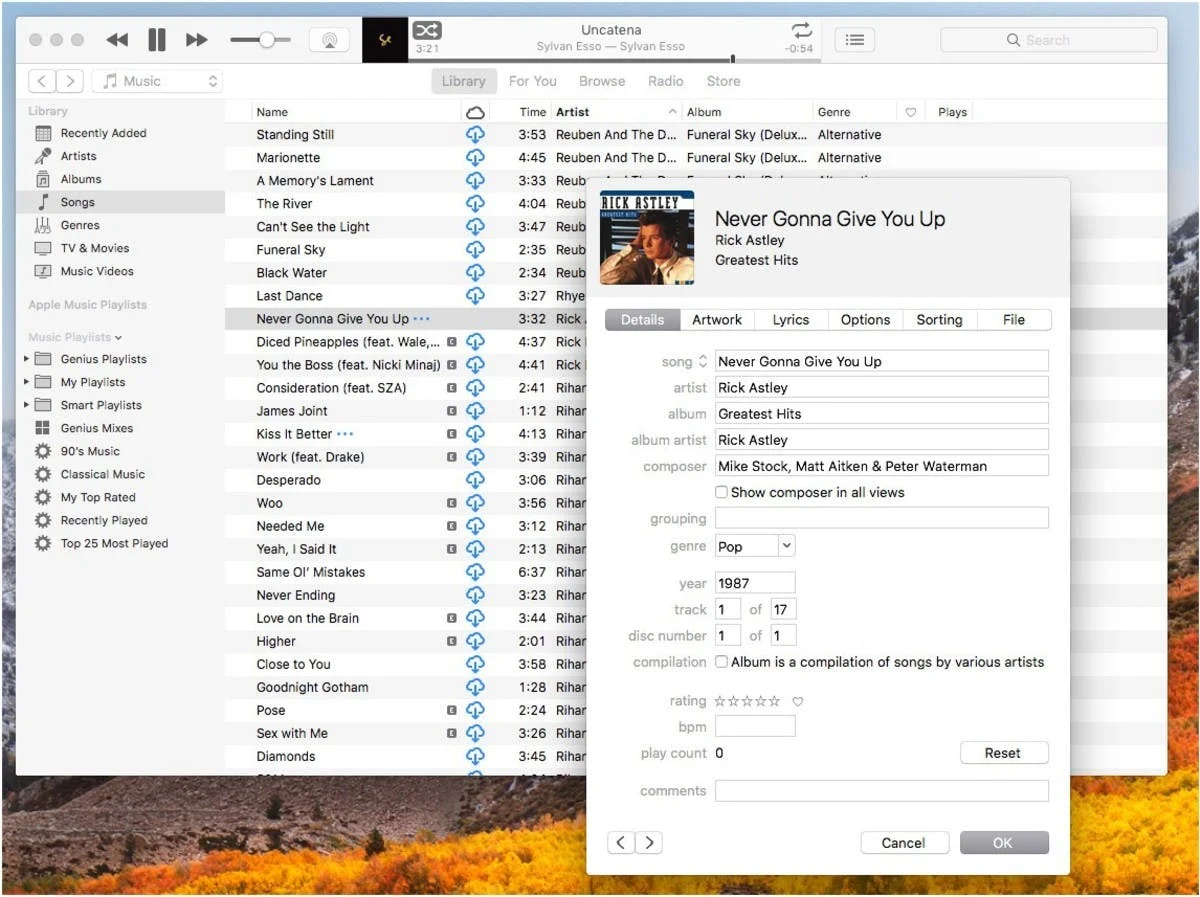
Erros de Artistas Compostos em Ação
Os Problemas dos Metadados Musicais
Neste ponto, um leitor curioso pode perguntar: mas se os metadados musicais são tão essenciais para o negócio da música, por que ainda não os corrigimos? Por que os compositores ainda estão perdendo dinheiro e por que o banco de dados do iTunes está cheio de erros de artistas compostos? Bom, o fato é que o sistema de gerenciamento de metadados musicais sempre ficou para trás em relação aos formatos de distribuição de áudio.
Por exemplo, quando o CD surgiu, não permitia nenhuma tag além dos dados descritivos básicos — as capas e livretos de CDs desempenhavam o papel de anexo de metadados. Então, o Napster tomou conta, e o caos veio junto. Os arquivos MP3 (ou FLAC) extraídos de CDs tinham quase nenhum metadado anexado, e ainda menos passavam pelas redes P2P, criando um enorme arquivo de arquivos de áudio mal tagueados.
1. Falta de Padronização do Banco de Dados
Então, a música digital entrou em cena e substituiu os formatos de gravação física. Todos os lados da indústria começaram a armazenar e trocar dados, mas naquela época, ninguém realmente via a necessidade de padrões de metadados unificados. Todas as diferentes lojas digitais, gravadoras, editoras, PROs e distribuidoras configuraram seus próprios bancos de dados — e os serviços de streaming seguiram seus passos.
Até hoje, não há uma estrutura de banco de dados unificada. Os metadados percorrem uma interligação não padronizada de bancos de dados em toda a indústria: de gravadoras a distribuidoras, de distribuidoras a DSPs, de DSPs a PROs, de PROs a editoras.
Todas essas partes estão trocando dados, mas as colunas e campos de seus bancos de dados nem sempre coincidem. Imagine que um banco de dados recebe um valor no campo "Back Vocalist" — quando sua própria coluna correspondente se chama "Back Vocals". Os algoritmos não conseguirão fazer essa correspondência (a menos que haja uma regra específica para isso) e em 99% dos casos, o crédito do backing vocal será simplesmente descartado. Uma grande parte dos metadados se perde em seu caminho pela cadeia de dados musicais.
Além disso, para cada empresa musical, raramente há um único banco de dados. Em vez disso, os dados são armazenados em várias bibliotecas musicais internas em diferentes formatos — e por isso precisam ser ajustados e validados para configurar uma troca adequada com bancos de dados externos.
O sistema atual de gerenciamento de metadados foi criado na esteira da música digital, quando ninguém realmente sabia como o cenário iria se desenvolver. Então, a produção de dados cresceu exponencialmente. Agora, 20.000 músicas são lançadas todos os dias e enviadas pelo intrincado sistema de bancos de dados nem sempre compatíveis — gerando milhares de erros.
Não se preocupe, o Spotify não é melhor
2. Multiplicidade dos Dados Musicais
O problema não é nem que existam 20 mil músicas. É também sobre o fato de que essas músicas podem ser diferentes variações da mesma obra musical. Vamos ficar um pouco técnicos por um momento. Cada música é estruturada por meio de três camadas de abstração:
- Uma obra musical ou composição — resultado do processo criativo dos compositores e produtores, base da editora musical.
- Uma gravação sonora da obra musical, produzida e gravada pelos artistas intérpretes. A gravação sonora é uma expressão particular da obra musical.
- Um lançamento — uma manifestação específica e embalada da gravação sonora.
Então, tudo começa com compositores criando uma obra musical. Então, essa composição pode ser expressa de centenas de maneiras diferentes — pense em versões cover, remixes, edições para rádio e assim por diante. Além disso, cada uma dessas gravações sonoras pode ser lançada como single, parte de um álbum, parte de uma edição deluxe, parte de uma coletânea etc.
No final, uma única composição pode criar centenas (se não milhares) de entidades de metadados separadas, o que complica enormemente o cenário. As empresas musicais precisam corresponder todas essas diferentes camadas de abstração. Por exemplo, se a ASCAP recebe um relatório de execução de rádio para um lançamento específico, ela precisa combiná-lo com a composição subjacente para localizar os compositores.
3. Deficiências do Padrão de Identificação Musical
Bom, alguém poderia pensar que a indústria musical desenvolveria um padrão para poder identificar qual lançamento é uma versão de qual gravação sonora e corresponder todas as camadas de abstração. Bom, não exatamente.
Atualmente, o principal padrão para identificação de música em todos os formatos de arquivo é o código ISRC — "um ponto fixo de referência quando a gravação é usada em diferentes serviços, além-fronteiras, ou sob diferentes acordos de licenciamento". No entanto, os códigos ISRC são atribuídos às gravações sonoras — apenas uma das camadas de dados musicais.
Apenas com o ISRC, você não conseguirá identificar qual é a obra musical original por trás daquela gravação específica. Ele não permite agregar as entradas no nível de abstração mais alto para compilar todas as versões da mesma faixa ou composição. Os limites do padrão ISRC tornam muito difícil para as empresas musicais corrigir metadados quebrados. Para dar sentido aos dados recebidos, os players da indústria precisam depender de tags de metadados descritivos para corresponder o ISRC a outros IDs persistentes, como UPC para lançamentos ou ISWC para composições. Isso resulta em todo tipo de erros, duplicatas e conflitos ao longo da cadeia de dados musicais.
Houve várias tentativas de criar um banco de dados de referência musical global, mas até hoje não existe uma fonte suprema da verdade que permita resolver os conflitos de metadados. Atualmente, os bancos de dados musicais públicos mais notáveis são as plataformas de código aberto MusicBrainz e Discogs e o catálogo de códigos ISRC da IFPI — mas, infelizmente, todos eles estão longe de ser completos.
As deficiências do sistema de ID significam que as empresas musicais precisam dar muitas voltas toda vez que encontram um erro de metadados. Tentar conectar os pontos cruzando referências em bancos de dados cheios de inconsistências é uma rotina diária do gerenciamento de dados musicais. Isso, se a empresa se importar o suficiente.

A Seção de Créditos de Músicas do Spotify Destaca os Problemas de Metadados de Propriedade
4. Erros Humanos
Por último, mas não menos importante, temos o que alguns chamariam de o elo mais fraco de qualquer sistema. A maior parte dos metadados descritivos e de propriedade é criada e preenchida manualmente. Considerando a escala, isso inevitavelmente leva a todo tipo de erros de digitação, nomes com erros ortográficos, títulos, datas de lançamento — ou até dados completamente ausentes.
Tome os dados de propriedade, por exemplo. Os créditos de uma música podem se tornar extremamente complicados, com dezenas de compositores, engenheiros, músicos de sessão e produtores diferentes trabalhando no mesmo lançamento. Ao mesmo tempo, os prazos não esperam — e assim os acordos de propriedade e divisões frequentemente são ignorados quando a equipe está tentando lançar a nova faixa no prazo. Muitas vezes, as divisões serão decididas após o fato — e uma vez que a música já está disponível, é extremamente difícil adicionar ou editar os metadados.
Todos esses fatores diferentes, desde erros humanos e incompatibilidade de bancos de dados até padrões de ID falhos e a natureza multifacetada dos direitos autorais musicais, criam a sombria realidade dos metadados musicais modernos. A espinha dorsal da indústria musical é talvez a maior bagunça que o mundo dos dados já viu.
Como Corrigimos os Metadados?
A situação atual de perda-perda está pedindo uma mudança. Metadados limpos poderiam ajudar um músico de sessão a conseguir o próximo trabalho, pagar o aluguel do compositor, otimizar a experiência do usuário nos serviços de streaming — e economizar milhões para a indústria ao longo do caminho. No entanto, não há uma resposta clara sobre como corrigir o problema. Não fique pessimista demais — há várias empresas, iniciativas e organizações trabalhando para um sistema melhor.
Soluções de Limpeza, Gerenciamento e Administração de Metadados
O primeiro tipo de empresas de metadados está trabalhando para montar bancos de dados musicais e depois limpar, corrigir e expandir as tags de metadados. Empresas como Gracenote, Musicstory e, em certa medida, The Echo Nest são provedores de metadados para vários DSPs no setor. Essas empresas se preocupam principalmente com metadados descritivos e de recomendação. Elas usam uma combinação de algoritmos de limpeza de metadados e tecnologia de reconhecimento de áudio para potencializar a busca, playlisting e descoberta de música, garantindo a exibição correta nas lojas digitais.
Do outro lado da cadeia de dados, empresas como VivaData, Exploration e TuneRegistry estão desenvolvendo soluções para gravadoras independentes, editoras e artistas. Seu objetivo é ajudar as empresas musicais com gerenciamento interno de metadados, auditar os bancos de dados existentes em busca de metadados incompletos/corrompidos e agilizar os fluxos de dados de saída na raiz do fluxo de dados musicais.
No entanto, todas essas empresas estão tratando os sintomas, e não a causa do problema. Não me entenda mal, é vital tentar limpar a bagunça existente — mas isso não resolverá os problemas sistemáticos.
Novos Padrões de Banco de Dados
Talvez a mudança mais significativa viesse se garantíssemos que os bancos de dados em toda a indústria musical fossem totalmente compatíveis. No entanto, a otimização do sistema de metadados de toda a indústria exigiria coordenação entre todos os lados do negócio, o que não é tarefa fácil.
O player mais visível nesse espaço é o DDEX, uma organização internacional que desenvolve e promove novos padrões e protocolos de dados para otimizar a cadeia de dados digitais. Oferecendo soluções que cobrem a totalidade do sistema de dados musicais, o DDEX já fez progressos significativos, contando com alguns dos maiores nomes da indústria como membros. Os padrões DDEX visam facilitar o gerenciamento de metadados no estúdio, harmonizar as transferências de metadados entre proprietários de conteúdo e DSPs e muito, muito mais.
Essencialmente, o objetivo da organização é construir um pipeline de ciclo completo para os metadados musicais, desde o ponto onde são criados até o destino final. Implementar protocolos de troca padrão para metadados musicais poderia potencialmente limpar a indústria de milhares de erros de incompatibilidade. No entanto, embora as iniciativas do DDEX possam ajudar a desenvolver um sistema melhor, isso não resolverá todos os problemas de metadados.
Para não soar como um clichê, mas quando se trata de corrigir os metadados, você precisa começar por si mesmo. Uma parte considerável dos erros deve-se à falta de conscientização entre os profissionais da música — o que é parte da razão pela qual escrevemos este artigo em primeiro lugar.
O que você pode fazer para ajudar a corrigir os metadados musicais?
A regra simples é garantir que todos os metadados da música estejam adequadamente preenchidos e verificados antes do lançamento da música (ou álbum). Isso não é tão fácil quanto parece. Aqui estão algumas dicas para ajudá-lo a garantir que você não contribua para o monte de metadados musicais corrompidos:
1. Acompanhe os Metadados Desde o Início
Cada música pode ter dezenas (se não centenas) de colaboradores, e por isso acompanhar todas as pessoas trabalhando no lançamento pode sair do controle muito rapidamente. Por isso é crucial acompanhar os créditos da música desde o momento em que há mais de uma pessoa envolvida no projeto.
Sound Credit e os Creator Credits da Auddly (o recurso ainda estava em desenvolvimento no momento da redação deste artigo) podem ajudar nisso. Essas soluções permitem incorporar créditos e outros metadados diretamente nos arquivos DAW que circulam pelo estúdio. Dessa forma, você pode manter os créditos no mesmo lugar e manter o registro consistente de todas as versões e colaboradores da música em todos os arquivos musicais.
2. Finalize os Acordos e Defina as Divisões Antes que a Música Saia do Estúdio
Os direitos musicais tendem a ficar muito complicados, e a pressa para cumprir o prazo de lançamento muitas vezes pode deixar os metadados de propriedade incompletos. No entanto, metadados de propriedade incompletos podem significar que alguns, ou até todos os colaboradores perderão o pagamento completamente. Para facilitar o lado contratual das coisas, considere usar Splits, um aplicativo gratuito criado para rastrear e gerenciar os colaboradores de uma música e, bem... as divisões.
3. Certifique-se de Que os Metadados Estão Preenchidos Corretamente
Os erros de digitação podem parecer insignificantes, mas têm um impacto real. O esboço da faixa será usado para fazer correspondências no banco de dados, e assim os metadados descritivos corrompidos tendem a quebrar as coisas. Certifique-se de verificar duas e três vezes os metadados da música antes de enviá-los — ou configure um sistema de verificação em duas etapas. Uma vez que a música esteja disponível, corrigir os erros de digitação se tornará muito problemático.
4. Siga as Diretrizes de Metadados
Não se trata apenas do que você coloca, mas também de como você formata esses dados. A diferença entre escrever o nome da música como "Nome da Música (Edição para Rádio)" e "Nome da Música — Edição para Rádio" pode não parecer muito, mas considere o seguinte. Os dados musicais são como uma sala cheia de espelhos falsos. Cada erro vai percorrer a indústria musical, se amplificando pelo labirinto de bancos de dados. Até o menor erro pode se tornar um problema real para um artista, com músicas acabando em uma página errada do Spotify ou royalties de execução se perdendo no caminho.
Para garantir que não apenas o conteúdo, mas também os formatos estejam corretos, você pode usar as diretrizes de metadados. Siga o guia da distribuidora — a maioria deles é fácil de seguir. Se as instruções da distribuidora não tiverem todas as respostas, consulte as diretrizes gerais como as fornecidas pela Music Business Association.
5. Espalhe a Palavra
Seguir esses passos, é claro, não corrigirá todos os problemas de metadados na indústria. O problema em si é muito complicado, e só podemos resolvê-lo se toda a indústria musical estiver na mesma página. Nesse sentido, o primeiro passo é aumentar a conscientização entre os profissionais da música.
Os metadados estão no núcleo da indústria musical, e agora estão quebrados. Os músicos perdem royalties. Os compositores e engenheiros não recebem o crédito que merecem. Os serviços de streaming desenvolveram algoritmos para garantir que o topo do catálogo pareça limpo, mas quando você mergulha fundo na cauda longa, todo tipo de erros começa a aparecer pelas rachaduras. Precisamos começar a avançar em direção a um sistema melhor.
Nós da Soundcharts fazemos o melhor possível com o sistema como ele é. Como plataforma de análise de dados, precisamos coletar dados de dezenas de fontes e bancos de dados sujos. Então, agregamos cuidadosamente os dados e cruzamos tags de metadados para garantir que cada posição de ranking, cada adição a playlist de streaming, cada execução de rádio e cada menção na imprensa digital seja adequadamente atribuída. Melhoramos continuamente nossos algoritmos de limpeza e correspondência de metadados, ao mesmo tempo que mantemos uma equipe dedicada de manutenção manual para resolver os problemas que escapam pelas rachaduras. É isso que nos torna a plataforma de análise musical mais limpa da indústria.

