

As a big data company tapping into dozens of data sources to build the data analytics tool of the music industry, Soundcharts deals with corrupted metadata every day. Over the years, we’ve developed several algorithms, that ensure sure that our database is as clean as it can be, but even now we have to keep up some sort of manual maintenance. Soundcharts’ team learned how broken music metadata can be the hard way — by managing a database of 2M+ artists.
But it's not only about us. The fact is that metadata issues cause a lot of damage to the industry. Compromised metadata hurts the user experience on the streaming services, cuts off a portion of publishing revenues, robs songwriters of well-deserved credit — and that’s just the beginning. But let’s start with the basics:
What is Music Metadata?
Music metadata is the identifying data embedded in a music file, comprised of hundreds of text-based meta tags that are attached via metadata containers (ID3v1 and ID3v2 being by far the most widespread), detailing everything from the artist’s name and the song’s release date to associated genres and songwriters credits.
At first, Metadata might sound like an insignificant little thing, but consider the following. Every time a user searches for a song on Spotify; every time BMI attributes performance royalties; every time Pandora’s algorithm queues up a song — metadata is at play. It’s the oil that makes the cogs of the industry spin.
3 Types of Music Metadata
Generally, music metadata can be divided into three main types:
1. Descriptive Metadata
Descriptive Metadata details the contents of the recording, with objective text tags like song title, release date, track number, performing artist, cover art, main genre and so on. It has about a million different applications. Descriptive metadata is used every time someone needs to query, organize, sort or present the music — whether it’s to put together an artist page on Spotify, build an organized music library, or identify and attribute a radio spin.
Descriptive metadata issues are the most visible to the end user. If you’ve been using any streaming service long enough, chances are you’ve stumbled upon the errors resulting from corrupted descriptions. Think of multiple artist’s songs mashed on the same Spotify artist page, compound artist pages, misspelled song names, mixed up release dates — all those are the consequences of compromised descriptive metadata. Such issues cause a great deal of confusion to the consumer — but that’s just the tip of the iceberg.
2. Ownership/Performing Rights Metadata
Whether we’re talking digital streams, airplay or movie synch, numerous parties, from performing artists to lyricists, producers and songwriters, will share the revenue. Hence the need for ownership metadata, specifying the contractual agreements behind the release for the purposes of royalty calculation (and allocation). Ownership metadata is there to make sure that each and every side taking part in music creation process, is remunerated accordingly.
Given the complex nature of splits behind most of the tracks (as well as differences in legislation across the globe) getting the consumer’s dollar divided up correctly is no small feat in itself. Now, if we add missing or inconsistent metadata in the mix, the issue becomes 10 times more complicated. Ownership metadata issues hit where it hurts the most: a human error here, a database glitch there — and a songwriter can miss out on tens of thousands of dollars.
However, that’s just part of the problem. The artist credits are also the primary way for songwriters, producers, session musicians, and engineers to make themselves visible to the music industry, a kind of “b2b” promotion space. Corrupted ownership metadata robs musicians of both money and credit.
3. Recommendation Metadata
The first two types of metadata tags are objective — there’s just one real song name, and just one list of song’s credits. Recommendation metadata is different. In its core, it consists of subjective tags that aim to reflect the contents of the recording and describe how it sounds. Mood labels, generative genre tags, song similarity scores — recommendation metadata is used to make a meaningful connection between tracks and power the recommendation engines.
Of course, other types of metadata can be used to enhance music discovery as well. The release dates can help you detect the music from the same era, and matching producer’s name can help find similar recordings. However, the critical distinction is the origin of recommendation metadata.
Discovery is a huge differentiator between the streaming services. That's why recommendation metadata tags are usually proprietary data that doesn’t travel the industry as descriptive and ownership meta does. Instead, each platform will have its own approach to recommendation metadata generation and its own database behind the recommendation algorithm. So, if description and ownership metadata is created on the artist's end, the recommendation meta is produced by the DSPs (or their affiliates).
For example, Pandora takes a human classification approach with its Music Genome Project. Spotify, on the other hand, employs a mix of user-generated data and The Echo Nest discovery meta tags, produced through a combination of machine learning and human curation. If you want to get a sneak peek into recommendation meta tags structure of The Echo Nest/Spotify and get a general idea of how recommendation meta looks like, check out Organize Your Music project.
Discovery metadata is the fastest developing subset of the entire landscape. The new tech is pushing the borders of discovery, calling for new solutions and approaches to recommendation.
Just think about how smart speakers will change the way we access and discover music. Voice-mediated music consumption turns users from structured text queries to amorphous requests along the lines of “Alexa, play something I like”. That brings a new challenge to the recommendation engines of streaming platforms and search engines like Google. It won’t be enough to find similar songs and generate radio-like song queues. Streaming platforms will have to figure out what is the best song to play to that exact person at that exact time. The way they approach this challenge will affect the livelihood of thousands of artists and music pros, shaping the future of the music industry for years to come.

Compound Artist Errors in Action
The Problems of Music Metadata
At this point, a curious reader might ask: but if the music metadata is so essential for the music business, why haven’t we fixed it yet? Why songwriters are still losing money and why iTunes database is full of compound artist’s errors? Well, the thing is that the music metadata management system was always dragging behind the audio distribution formats.
For example, when CD first came about, it didn’t allow for any tags apart from the basic descriptive data — CD cases and booklets played the role of metadata attachment. Then, Napster took over, and the chaos followed with it. The MP3 files (or FLAC files) ripped from CDs had next to no metadata attached, and even less made it over the P2P networks, creating a massive archive of poorly tagged audio files.
1. Lack of Database Standardization
Then, the digital music entered the stage and replaced the physical recording formats. All the sides of the industry began to store and exchange data, but back in the day, no one really saw the need for unified metadata standards. All the different digital storefronts, labels, publishers, PROs and distributors set up their own databases — and the streaming services followed in their footsteps.
Up to this date, there’s no unified database structure. Metadata runs through an unstandardized intertwinement of databases across the industry: from labels to distributors, from distributors to DSPs, from DSPs to PROs, from PROs to publishers.
All those parties are exchanging data, but the columns and fields of their databases don’t always match up. Imagine that a database receives a value in the field “Back Vocalist” — when its own corresponding column is called “Back Vocals”. Algorithms won’t be able to make that match (unless there’s a specific rule for it) and in 99% of the cases, the back vocalist's credit will just get scraped. A big chunk of metadata gets lost on its way through the music data chain.
Furthermore, for each music company, there’s rarely a single database. Instead, the data is stored across multiple internal music libraries in different formats — and so it needs to be adjusted and validated to set up a proper exchange with external databases.
The current metadata management system was created in the wake of digital music when no one really knew how the landscape is going to develop. Then, data production grew exponentially. Now, 20,000 songs are released every day and pushed through the intricate system of not-all-that-compatible databases — spawning thousands of errors.
Don't worry, Spotify is not any better
2. Multiplicity of the Music Data.
The problem is not even that there are 20 thousand songs. It’s also about the fact that those songs can be different variations of the same musical work. Let’s get a bit technical for a moment. Every song is structured through three layers of abstraction:
- A musical work or composition — a result of the creative thought process of songwriters and producers, bread and butter of music publishers.
- A sound recording of the musical work, produced and recorded by performing artists. Sound recording is a particular expression of the music work
- A release — a specific, packaged manifestation of the sound recording.
So, it all starts with songwriters and composers creating a musical work. Then, that composition can be expressed in a hundred different ways — think of cover versions, remixes, radio edits, and so forth. Furthermore, each of these sound recordings can be released as a single, a part of an album, a part of a deluxe edition, a part of a compilation, etc.
In the end, a single composition can create hundreds (if not thousands) of separate metadata entities, which hugely complicates the landscape. Music companies need to match all those different layers of abstraction. For example, if ASCAP gets a report of a radio spin for a specific release, it needs to pair it with the underlying composition to locate songwriters.
3. Shortfallings of Music ID Standard
Well, one would think that the music industry would develop a standard to be able to tell which release is a version of which sound recording and match all the layers of abstraction. Well, not really.
Currently, the primary standard for music identification across all file formats is the ISRC code — “a fixed point of reference when the recording is used across different services, across borders, or under different licensing deals”. However, ISRC codes are assigned to sound recordings — just one of the layers of music data.
Based on ISRC alone, you won’t be able to tell what is the original musical work behind that particular recording. It doesn’t allow to aggregate the entries to the higher level of abstraction to compile all the versions of the same track or composition. The limits of ISRC standard make it really hard for music companies to fix broken metadata. To make sense of the incoming data, the industry players have to rely on descriptive metadata tags to match the ISRC with other persistent IDs, like UPC for releases or ISWC for compositions. That results in all sorts of errors, duplicates, and conflicts across the music data chain.
There were several attempts to create a global music reference database, but up to this date, there is no ultimate source of truth that would allow resolving the metadata conflicts. Now, the most notable public music databases are MusicBrainz and Discogs open-source platforms and IFPI’s ISRC code catalog — but, unfortunately, all of them are far from complete.
The shortfallings of the ID system mean that music companies have to go through hoops every time they encounter the metadata error. Trying to connect the dots by cross-referencing the databases that are full of inconsistencies themselves is a daily routine of music data management. That is, if the company cares enough.

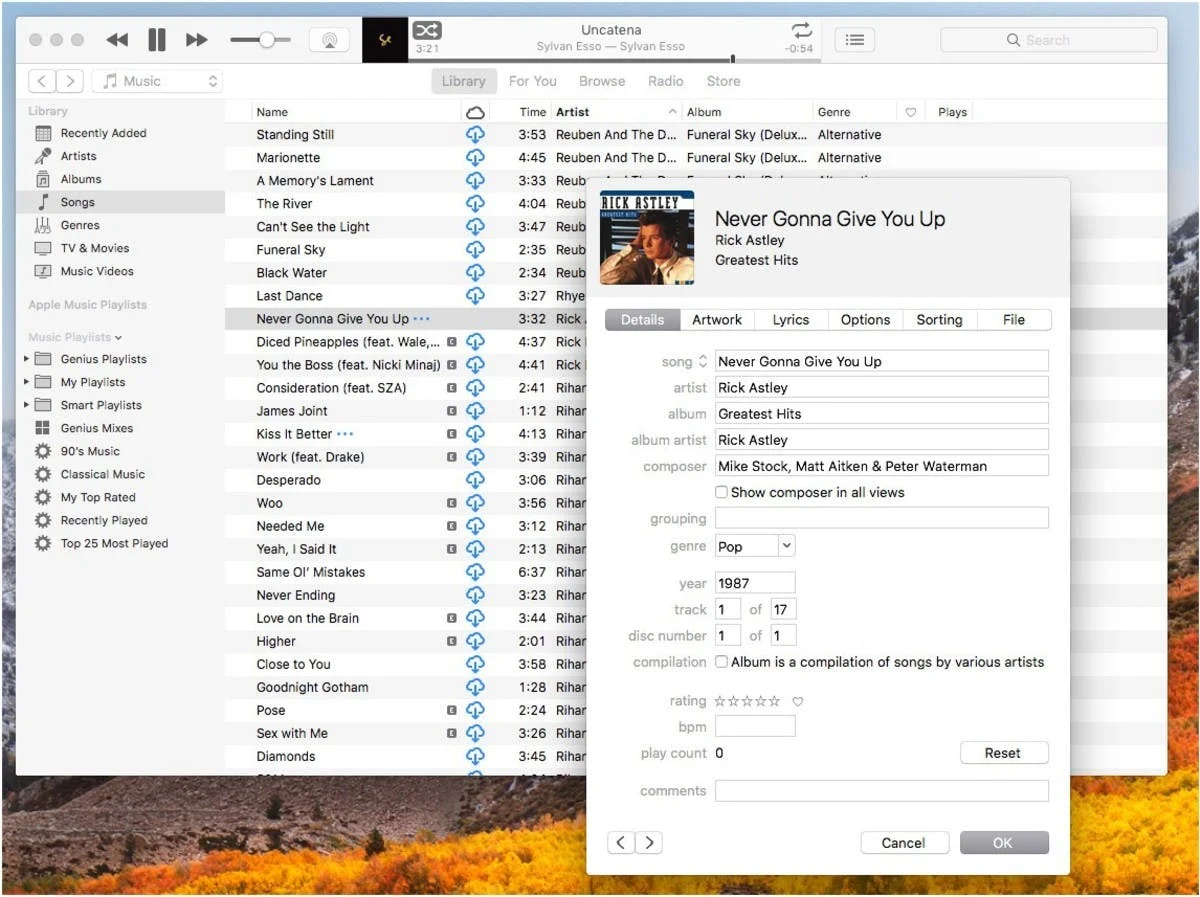
Spotify Song Credits Section Highlights the Ownership Metadata Issues
4. Human Errors
Last, but not least, we have what some would call the weakest link of any system. Most of descriptive and ownership metadata is created and filled in manually. Considering the scale, that inevitably leads to all sorts of typos, misspelled names, titles, release dates — or even straight-up missing data.
Take the ownership data, for example. Song’s credits can become extremely complicated, with dozens of different songwriters, engineers, session musicians and producers working on the same release. At the same time, the deadlines won’t wait — and so the ownership agreements and splits often get overlooked when the team is trying to push out the new track on time. Quite often, splits will be decided after the fact — and once the song is already out, it’s extremely hard to add or edit the meta.
All those different factors, from human errors and database incompatibility to flawed ID standards and multi-sided nature of music copyrights, create the grim reality of the modern music metadata. The backbone of the music industry is perhaps the biggest mess the data-world has ever seen.
How Do We Fix the Metadata?
The current lose-lose situation is calling for a change. Clean metadata could help a session musician get the next gig, pay the songwriter’s rent, optimize user experience for streaming services — and save millions to the industry along the way. However, there’s no clear answer as for how do we fix the problem. Don’t get too pessimistic, though — there’s several companies, initiatives, and organizations working towards a better system.
Metadata Clean Up, Management and Administration Solutions
The first type of metadata companies are working towards putting together music databases and then cleaning, mending, and expanding the meta tags. Companies like Gracenote, Musicstory and, to some extent, The Echo Nest are the metadata providers for various DSPs across the industry. Such companies are primarily concerned with descriptive and recommendation metadata. They use a mix of metadata cleaning algorithms and audio-recognition tech to empower search, playlisting, and music discovery while ensuring correct display for the digital storefronts.
On the other side of the data chain, companies like VivaData, Exploration and TuneRegistry are working out solutions for independent record labels, publishers and artists. Their aim is to help music companies with internal metadata management, audit the existing databases for incomplete/corrupted metadata and streamline outgoing data flows at the very root of the music data flow.
However, all those companies are treating the symptoms, and not the cause of the issue. Don’t get me wrong, it’s vital to try and clean up the existing mess — but that won’t solve the systematic problems.
New Database Standards
Perhaps the most significant shift would come if we ensure that the databases across the music industry are fully compatible. However, optimization of the industry-wide metadata system would take coordination between all the sides of the business, which is no easy task.
The most visible player in that space is the DDEX, an international organization developing and promoting new data standards and protocols to optimize the digital data chain. Offering solutions covering the entirety of the music data system, DDEX has already made significant progress, counting some of the biggest names in the industry as its members. DDEX standards aim to facilitate metadata management in the studio, harmonize the metadata transfers between content owners and DSPs and much, much more.
Essentially, the goal of the organization is to build a full-circle pipe for the music metadata, from the point where it’s created to the final destination. Putting in place standard exchange protocols for music metadata could potentially cleanse the industry from thousands of incompatibility errors. However, while the DDEX initiatives can help develop a better system, that won’t fix all of the metadata issues.
Not to sound cliché, but when it comes to fixing the metadata, you have to start with yourself. A considerable portion of errors is due to the lack of awareness amongst music professionals — which is part of the reason we wrote this article in the first place.
What you can do to help fix the music metadata?
The simple rule of thumb is to make sure that all of the song’s metadata is adequately filled out and verified before the song (or album) release. That’s not as easy as it sounds. Here’s some advice to help you make sure that you won’t contribute to the pile of corrupted music metadata:
1. Keep Track of the Metadata From the Get-Go
Each song can have dozens (if not hundreds) or contributors, and so keeping track of all the people working on the release can get out of hand really quick. That’s why it’s crucial to keep track of the song’s credits from the very moment there’s more than one person involved with the project.
Sound Credit and Auddly’s Creator Credits (the feature was still in development at the moment of writing this article) can help you there. Those solutions allow embedding credits and other metadata directly into the DAW-files that fly around the studio. That way you can keep credits in the same place and maintain the consistent record of all song versions and collaborators across all music files.
2. Finalize Agreements and Define Splits Before a Song Leaves the Studio
Music rights tend to get very complicated, and the rush to meet the release deadline can often leave the ownership metadata incomplete. However, incomplete ownership metadata can mean that some, or even all of the collaborators will miss out on the pay check completely. To make the contractual side of things easier, consider using Splits, a free application created to track and manage a song’s collaborators and, well... splits.
3. Make Sure That the Metadata is Filled Correctly
The typos might seem insignificant, but they really have an impact. Track outline will be used to make matches in the database, and so corrupted descriptive metadata has a tendency of breaking things. Be sure to double- and triple-check the song’s metadata before you send it out — or set up a two-step vetting system. Once the song is out there, fixing the typos will become very problematic.
4. Follow Metadata Guidelines
It’s not only about what you put in, but also about how you format that data. The difference between writing out the song name as “Song Name (Radio Edit)” and “Song Name — Radio Edit” might not seem like much, but consider the following. Music data is like a room full of false mirrors. Every error will travel the music industry, getting magnified on its way through the maze of databases. Even the smallest mistake can turn into the real issue for an artist, with songs ending up on a wrong Spotify page or performance royalties getting lost in the mail.
To make sure that not only the contents but also the formats are correct, you can use metadata guidelines. Stick with the distributor’s guide — most of them are easy to follow. If the distributor’s instructions don’t have all the answers, check in with the general guidelines like the one provided by the Music Business Association.
5. Spread the Word
Following those steps, of course, won’t fix all the metadata issues in the industry. The problem itself is too complicated, and we can only solve it if the entire music industry is on the same page. In that sense, the first step is to raise awareness amongst the music professionals.
Metadata is at the core of the music industry, and right now it’s broken. Musicians miss out on royalties. The songwriters and engineers don’t get the credit they deserve. The streaming services have developed algorithms to make sure that the top of the catalog looks clean, but once you take a deep dive on the long tail, all sorts of errors start falling through the cracks. We need to start moving towards a better system.
We at Soundcharts do the best we can with the system as it is. As a data analytics platform, we have to draw in the data from dozens of sources and dirty databases. Then, we carefully aggregate the data and cross-check meta tags to ensure every chart position, every streaming playlist addition, every radio spin and every digital press mention is properly attributed. We continuously improve our metadata cleansing and matching algorithms, all while keeping a dedicated manual maintenance team to tackle the issues that do slip through the cracks. That’s what makes us the cleanest music analytics platform in the industry.

